
Our reviewers evaluate career opinion pieces independently. Learn how we stay transparent, our methodology, and tell us about anything we missed.
Our reviewers evaluate career opinion pieces independently. Learn how we stay transparent, our methodology, and tell us about anything we missed.
When I was writing software documentation for NewBlue in my early 20s, I felt the pain DITA was built to solve, even though we were not using DITA. We had the same concepts and steps showing up in multiple places, and every product update turned into a scavenger hunt for what needed changing.
Later, as I began to see how larger documentation teams operate, the pattern became obvious. The teams that ship at scale treat content like an asset, not like a Word file someone updates “when they have time.”
I know DITA can sound intimidating if you have only written in Google Docs, Confluence, or Markdown. My goal in this updated guide is to make it feel practical, not academic, so you can tell whether DITA is worth it for your team.
I’m going to walk you through DITA the same way I’d explain it to a new writer on my team. We’ll cover where it came from, how the structure works (topics and maps), what makes reuse and modularity possible, how specialization and metadata fit in, and what implementation looks like in the real world.
Then I’ll compare DITA to other common architectures and standards, because the best format is the one that fits your workflow and constraints. If you want a broader foundation first, my guide on what technical writing is can help you zoom out before you dive into structured authoring.
DITA stands for Darwin Information Typing Architecture, and the “Darwin” part is not just branding. The whole idea is that content evolves through reuse and inheritance, with more specific content types growing from a stable base.
IBM created DITA to solve a pretty classic enterprise problem: too many documents, too much duplication, and too many updates that required editing the same information over and over. IBM later donated DITA to OASIS, and the standard is maintained by the OASIS DITA Technical Committee, as you can see on the OASIS DITA Technical Committee page.
In plain terms, DITA exists to help teams write once, reuse safely, publish to multiple deliverables, and keep content consistent over time. If you have ever fixed the same instruction in five different places and still missed one, you already understand the “why.”
DITA is XML-based because XML’s strictness supports long-term consistency. It forces structure, supports validation, and plays nicely with automation, which matters when you publish at scale.
Structured authoring is the bigger concept here. You are not just writing text, you are tagging meaning. If you want a simpler primer on that mindset, my walkthrough of what XML authoring is explains how structure changes the way you write and edit.
This is also where DITA differs from “generic XML.” DITA is not just a markup language; it’s a content architecture plus a writing methodology, which I break down in my comparison of XML vs DITA if you want the longer explanation.
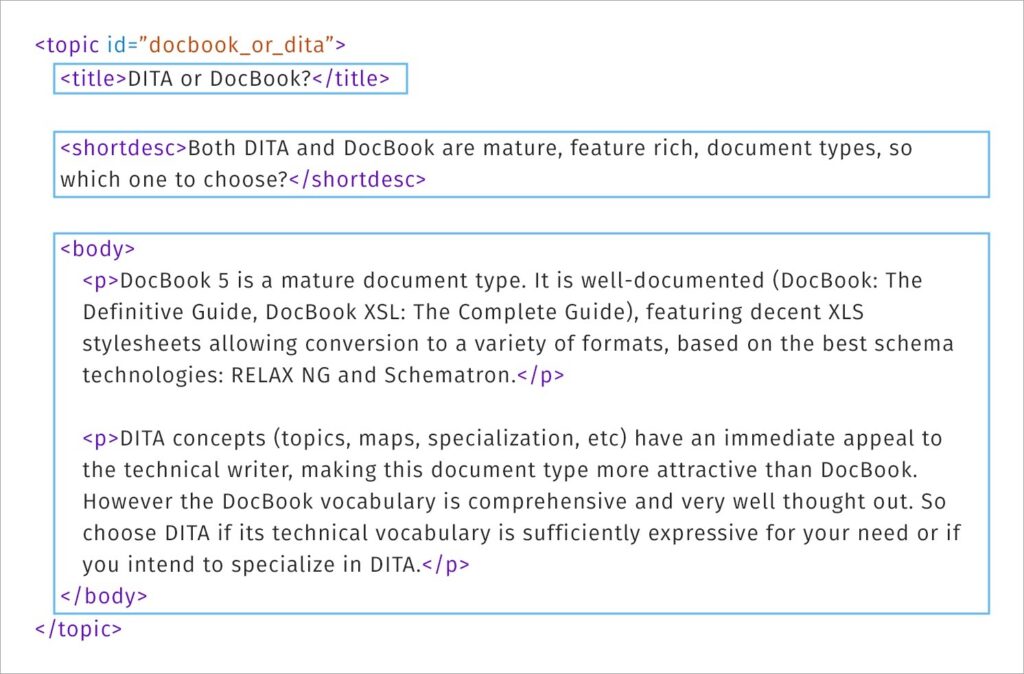
The core building block in DITA is the topic. A topic is a small, self-contained unit of information that covers one idea or user goal, making it easier to reuse, maintain, and translate.
DITA also encourages information typing, meaning you choose a topic type that matches the content’s intent. The classic three are concept, task, and reference, and that trio alone clears up a lot of documentation mess because it stops you from mixing definitions, steps, and tables into one muddy page.
In practice, teams add other types, such as troubleshooting and glossary entries, when building user-facing help systems. The bigger win is not the labels themselves, it’s the discipline of writing each piece of information in the format that makes it easiest to use.
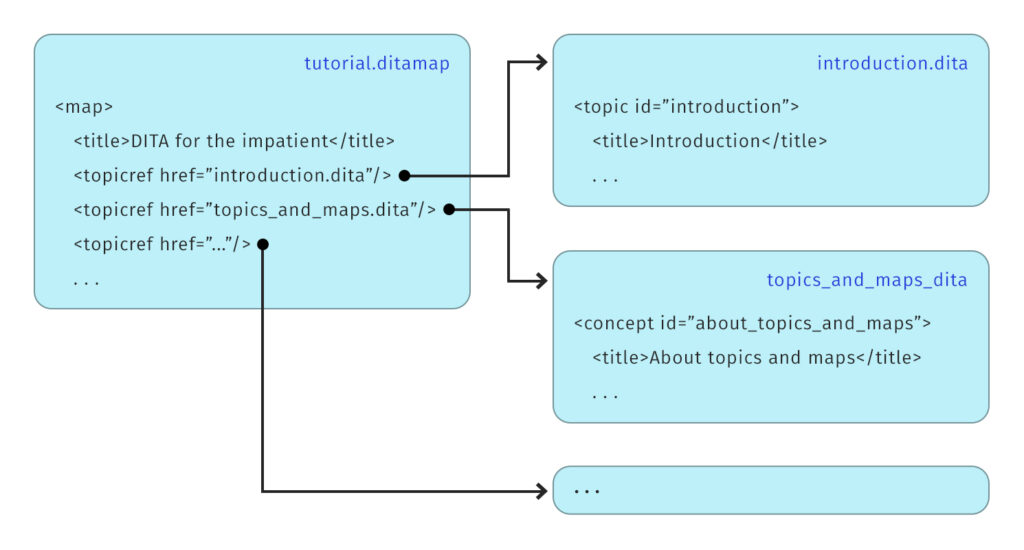
If topics are your Lego bricks, DITA maps are the instruction manual that assembles them. A DITA map defines hierarchy, sequence, and relationships, and it’s how you turn a library of topics into a specific deliverable.
Maps are also where DITA starts to feel like a real content architecture instead of just a writing format. You can create different maps for different audiences or products, while reusing many of the same underlying topics.
There are specialized map types too, and you will see names like bookmap (book-like outputs), learning maps (training content), classification maps, and subject scheme maps. Even if you never use all of them, it helps to know they exist because they show how DITA supports very different deliverables without changing the core writing model.
Content reuse is the feature everyone sells, but modularity is what makes it sustainable. DITA nudges you to design content in chunks that can stand alone, reducing duplication and making updates safer.
This is where mechanisms like content references come into play. You will hear terms like conref (pull content from another topic), conkeyref (key-based content reuse), and transclusion (the general idea of including content by reference). The key point is that DITA is designed to reuse content without copy-paste.
Conditional publishing is the other half of reuse. You can write a single set of topics and publish variants for different products, roles, or platforms using profiling attributes and DITAVAL files, which is one reason DITA is so popular in organizations with multiple product lines.
If you want the conceptual version of this, my guide on single-source authoring explains the strategy behind “create once, publish many” without getting bogged down in implementation details.
Specialization is one of the most “DITA” parts of DITA. It lets you extend the standard in a controlled way, so your organization can add domain-specific elements without breaking interoperability.
The best way to think about it is this: you can keep the base language stable, while giving your content more precise semantics where you need them. That matters in regulated or technical environments where generic labels are not enough.
Metadata is another quiet power feature. You can tag content for findability, reuse rules, audience targeting, and governance, and push that metadata through maps to keep it consistent across large outputs.
Subject scheme specialization is how teams keep metadata from turning into chaos. Subject schemes define controlled values for attributes, so instead of everyone inventing their own tags, you get a consistent taxonomy that supports search, filtering, and clean reuse logic.
Most DITA implementations have three moving parts: an authoring environment, a management layer, and a publishing pipeline. The authoring environment is a DITA-compliant XML editor or a specialized editor that supports validation and structured views.
The management layer is often a component content management system (CCMS) or a structured CMS that handles versioning, reuse governance, permissions, and audit trails. This is where collaboration becomes real, because multiple writers and reviewers can work inside a single source of truth instead of emailing attachments around.
Then there’s publishing. The most common engine is DITA-OT, an open-source toolkit you can explore on the DITA Open Toolkit website. In many teams, DITA-OT sits within a CI pipeline, making publishing repeatable and aligned with the product’s release rhythm.
If you are trying to connect DITA to modern versioning workflows, it helps to understand how content changes are tracked and reviewed. My guide on document version control is not DITA-specific, but the mindset translates to structured content workflows.
The biggest benefit of DITA is scalability. When your documentation grows into hundreds or thousands of pages across products, languages, and audiences, the “just write another page” approach stops working.
DITA also improves collaboration by encouraging shared standards. When writers, editors, SMEs, and localization teams are all working from structured content, you can build workflows that are repeatable instead of heroic.
Translation support is a major reason enterprises adopt DITA. Modular topics make translation packages smaller and more consistent, and reuse means you translate less overall because repeated content can be tracked and reused across deliverables.
DITA is used in software, telecom, semiconductors, medical devices, and any field where documentation must be accurate, consistent, and delivered in multiple formats. When the cost of getting docs wrong is high, structured authoring stops being a preference and starts being risk management.
If you are choosing an architecture, DITA is not competing with “writing.” It’s competing with other ways of structuring and governing content, like Markdown docs-as-code, DocBook, custom XML schemas, and standards like S1000D in aerospace and defense.
Compared to Markdown, DITA is heavier but offers stronger semantics, more reuse mechanisms, and more consistent multi-channel publishing. If your docs are small and fast-moving, Markdown might be enough, but if your content is repetitive and translated, DITA starts to pull ahead.
Compared to DocBook, DITA is more topic-oriented and reuse-oriented, while DocBook is more document-oriented. A lot of teams choose based on whether they are building modular help content (DITA) or book-like narratives (often DocBook), and the tooling ecosystem matters as much as the schema.
Compared to S1000D, DITA is more flexible and broadly applicable, while S1000D is prescriptive and tied to specific industry requirements. If you are in an industry that mandates S1000D, that decision is made for you, but DITA can still show up in adjacent documentation systems.
One nuance I see more in 2026 is Lightweight DITA (LwDITA), which aims to bridge structured semantics with authoring formats like Markdown and HTML5. If your team wants structure but cannot stomach full XML authoring everywhere, LwDITA is worth knowing about.
Here’s the honest rule I use: DITA is worth it when you have enough content complexity that structure saves you more time than it costs you to implement. Complexity shows up as repeated content, multiple deliverables, multiple products, multiple languages, or compliance-heavy review cycles.
When I was early in my career, the biggest documentation failures I saw were not “bad writing.” They were maintenance failures in which the docs drifted out of sync because nobody could keep up with the update load.
DITA does not magically fix that, but it provides the architecture to build a maintainable system. If your team is already feeling the pain of duplication, inconsistent terminology, and messy publishing, DITA is one of the cleanest long-term solutions I know.
If you are still evaluating your tool stack more broadly, it can help to compare what different teams use in practice. My roundup of software documentation tools gives you a broader view of the ecosystem for authoring, managing, and publishing.
Technical writing teams do not adopt DITA because it’s trendy. They adopt it because at a certain scale, structure becomes the only way to stay sane.
If you are working solo or in a small team with a single product and a single output, DITA might be overkill today. If you are supporting a growing product suite, translations, and multiple channels, learning DITA is one of the most practical career moves you can make.
Check out our Technical Writing Certification Course to learn more about becoming a successful technical writer.

Here I answer the most frequently asked questions about DITA.
DITA stands for Darwin Information Typing Architecture. It’s a structured approach to creating technical content using topic-based writing and standardized information types.
The “Darwin” part refers to how content can evolve through reuse and specialization, with new types growing from existing base structures.
Yes, for enterprise documentation where reuse, translation, and multi-channel publishing are unavoidable. DITA is less about trends and more about solving scale problems that never go away.
If anything, modern publishing pipelines make DITA more relevant because structured content integrates with automation and repeatable builds.
No, but a CCMS is where you get the biggest operational benefits around reuse governance and collaboration. You can author DITA in a file-based workflow and publish with a toolkit.
The tradeoff is that without a CCMS, you may have to build more governance, reuse tracking, and review discipline yourself.
A topic is a single unit of information, like one concept, one task, or one reference chunk. A map is a structure that organizes topics into a deliverable, such as a help system, guide, or manual.
If topics are your building blocks, maps are the blueprint that determines what gets included, in what order, and how they relate.
DITA reuse works by referencing content instead of copying it. That can mean reusing whole topics, pulling specific elements from another topic, or using keys and variables to reuse content safely across many outputs.
The practical result is that you update content once and publish the change everywhere it’s used, which is the opposite of the “fix it in five places” workflow.
You can learn the basic concepts, topic types, and map structure in a few days of focused practice. Getting comfortable with reuse strategies, conditional publishing, and specialization takes longer because it depends on the project’s complexity.
Get the weekly newsletter keeping 23,000+ technical writers in the loop.
Learn documentation engineering and advance your career.
Please check your email for a confirmation message shortly.













Get our #1 industry rated weekly technical writing reads newsletter.
Your syllabus has been sent to your email







